Frequently Asked Questions
Here you’ll find answers to frequently asked questions. If you have further questions or remarks concerning crawlOPTIMIZER just write us an e-mail.
FIRST STEPS
Is the crawler GDPR compliant?
Yes, of course!
We comply with the privacy policy and data protection guidelines. We do not store or analyze any individual’s personal information or individual-related data. We simply analyze Googlebot’s data.
The server location is in Germany.
Which payment plan should I choose?
For example, if your website has between 25,000 and 75,000 daily Googlebot requests, you should choose the MATT plan.
Our rates change based on your website’s Google requests per day, as well as the storage-duration of your log files. While the MATT version allows a maximum of 75,000 daily Googlebot requests, the LARRY tariff includes a maximum of 500,000 Googlebot requests per day. In case you need more than 500,000 requests per day, please contact us so we can arrange a personalized offer for your website.
Conclusion: In Google Search Console, find out how many daily requests your website has averaged over the past 90 days and use that number to select the appropriate plan.
If you do not have access to your website’s Google Search Console data – that’s no problem either. Simply choose one of our payment plan options and inform us via E-Mail about your decision. Afterwards, we will be able to track your website’s total daily requests for a month and inform you about the appropriate payment plan.
Will the introductory price expire?
No. The previously concluded introductory price has no time restriction and therefore will apply over the entire contract period.
What happens if I exceed the maximum requests per day?
This is not the end of the world.
If, however, you exceed your tariff’s average limit of requests over a constant period of 90 days, we will consult with you and adjust the tariff in a fair manner.
What happens after my order was placed?
Once your order has been approved, we will set up your own space/infrastructure on one of our servers.
Once this first step has been concluded (takes a maximum of one workday), we will notify you by E-Mail. The E-Mail will give you instructions on how you’ll be able to send us your logfiles.
Once we receive all the needed information, we’ll begin setting up your account (the setup has to be arranged only once).
Conclusion: One week after you have made your order, you should be ready to start analyzing your logfiles.
Will the tool’s analyses & evaluations be updated daily?
Yes, data will be drawn from the day before.
The log data is always drawn on a daily basis. In the night starting at approx. 00.00 o’clock, the previous day’s log data will be fetched and saved. Once completed, the crawlOPTIMIZER will begin with all necessary aggregations, so that all analyzes & evaluations will be ready for you the very next morning. You’ll be able to analyze your saved logfiles up to 60 months.
Is there live monitoring for the Googlebot?
No, there are currently no plans for this feature.
Due to the enormous complexity of the finished analyzes and evaluations; which utilizes a lot of server resources, LIVE monitoring is unfortunately not feasible. In return you will receive ready-to-use analyzes and evaluations that will make your professional life significantly easier.
You’ll be able to analyze and evaluate log files from the day before up to logfiles from 60 months ago.
INITIAL SETUP
How can I submit my logfiles to the crawloptimizer?
We offer you four easy ways to submit your log files automatically. The setup has to be arranged only once and is not too complex either.
- FTP(S) download
We get our own, secure access to your FTP(S) server (also secured via IP access), where your log files are stored daily. We will automatically download the log files on a daily basis. - FTP upload
We provide you with your own FTP server. You will get all access data & access rights from us. You will upload your log files daily and fully automated on our FTP server. - CURL download
We will get access via URL to download your log files daily. - Daily by E-Mail (suitable for small to medium websites)
You can send us your compressed log files daily by e-mail. For this you’ll receive your own e-mail address from which you will be able to send us your logs. Please note however, that each E-Mail should not exceed 10MB. Of course, you can send us several E-Mails of 10MB per day.
If you prefer another variant that is not listed here, just let us know and we will arrange anything according to your desires.
How do I know if my logfiles are suitable for the crawlOPTIMIZER?
Basically, we can use any log files from all different servers (Apache, nginx, etc.), due to the fact that all log files undergo a unique and individual setup. Log files in JSON format can also be processed without any problems.
Nevertheless, you are welcome to send us an excerpt of your logfiles by E-Mail. We check them and give you feedback as soon as possible.
Does the IT have to prepare or prefilter the logfiles?
Yes, please.
Since we do not want to process USER-related data, IT must perform the following prefiltering of the log files:
Pre-filtering the access logs for the term “google” within the “User Agent”. Therefore, the term “google” must appear within the User-Agent-String (no matter in which spelling). Examples: Googlebot, google, Google, GOOGLE). Ideally, we do not want to receive all other log entries without “google” and should therefore not be filed / transmitted.
Two examples:
• Mozilla / 5.0 (Linux, Android 6.0.1, Nexus 5X Build / MMB29P) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 41.0.2272.96 Mobile Safari / 537.36 (compatible; Googlebot / 2.1; http://www.google.com / bot.html)
• Googlebot-Image / 1.0
If other log entries have been transmitted by mistake, these will be identified by an automatic check during the logfile import and will be irrevocably deleted.
How do you determine the real Googlebot?
Through reverse-DNS we will test every unknown IP in order to find out if it stems from Google.
Our engine is self-learning, and automatically expands the number of known Google IPs to make matching even faster.
Do you also crawl my website?
Yes! In order to be able to use the crawlOPTIMIZER in its entirety, it is necessary to crawl your website(s). The crawling occurs once a week at night and will be set according to your individual requirements.
What are we crawling?
Our crawler just crawls all the entries (URLs) from your XML-Sitemaps.
The following crawling defaults are stored in the settings:
• Sitemap Import Weekday: Monday
• Sitemap Import Time: 01:00:00 (CET)
• Crawl Start Time: 02:00:00 (CET)
• Crawl End Time: 06:00:00 (CET)
• Crawl Rate: 5 URLs per second
These default values can be customized in the menu under “Settings” at any time by the customer himself.
In case you don’t want the XML-Sitemap(s) to be crawled, you’ll have to set the Crawl Rate to a value of “0”. This can also be done in the “Settings” menu as well. This would mean that the crawlOPTIMIZER won’t undergo crawling. In the case of a non-crawling of the Sitemaps, the “Do not waste your crawl budget (XML-Sitemap Check)” report cannot be displayed in the dashboard, because the crawling information will be missing.
Additional Information:
• The maximum crawl rate that can be set in the “Settings” menu is limited to 10 URLs per second. Higher crawl rates are only possible by request.
• The crawlOPTIMIZER User Agent is structured as follows:
Mozilla / 5.0 (compatible; crawlOPTIMIZER / 0.0.1; + https: //www.crawloptimizer.com)
What is your User Agent?
Mozilla/5.0 (compatible; crawlOPTIMIZER/0.0.1; +https://www.crawloptimizer.com)
GOOGLE SEARCH CONSOLE
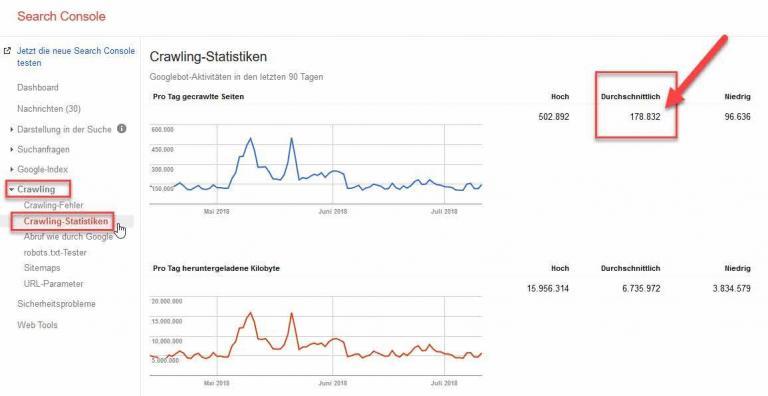
Where can you find the number of Googlebot-requests in Google Search Console?
- Sign into your Google Search Console
- If you’re logged in and click on this link, it should bring you directly to the “Average Crawls” section:
- https://www.google.com/webmasters/tools/crawl-stats
- Click on „Crawling”
- Afterwards, click on „Crawling Statistics”
- This is where you’ll be able to find the „Average Crawls”
Contact Us






