Häufig gestellte Fragen
Hier findest Du Antworten auf gängige Fragen. Wenn Du weitere Fragen oder Anmerkungen zum crawlOPTIMIZER hast, dann schreibe uns einfach eine E-Mail
(1/2) @g33konaut @methode @JohnMu The past few weeks I've been my own crawler & indexer, collecting data from all sorts of specific resources over the internet & podcasts to put together a big picture of the Google indexing process. It's of course incomplete & greatly simplified! pic.twitter.com/5NmJI26pNW
— Jan-Peter Ruhso (@JanRuhso) October 29, 2021
ERSTE SCHRITTE
Ist der crawlOPTIMIZER DSGVO konform?
Ja, selbstverständlich!
Wir halten uns an die Datenschutzrichtlinien. Es werden KEINE personenbezogenen Daten gespeichert oder analysiert, sondern lediglich die Daten des Googlebots.
Der Serverstandort befindet sich in Deutschland.
Welchen Tarif soll ich wählen?
Beispiel: Wenn Deine Webseite zwischen 25.000 und 75.000 Google-Bot Requests pro Tag hat, solltest Du den Tarif MATT wählen.
Unsere Tarife unterscheiden sich bei den maximalen Google-Requests pro Tag und der Dauer der Logdatenspeicherung. Während die MATT-Version eine maximale Anzahl an Google-Bot Requests pro Tag von 75.000 zulässt, hat man im Tarif LARRY eine maximale Anzahl von 500.000 Google-Requests pro Tag inklusive. Solltest Du mehr als 500.000 Requests pro Tag benötigen, nimm bitte persönlich mit uns Kontakt auf, damit wir Dir ein maßgeschneidertes Angebot legen können.
Fazit: Schaue in der Google Search Console nach, wie viele Requests Deine Webseite pro Tag im Durchschnitt der letzten 90 Tage hatte und wähle anhand dieser Zahl den passenden Tarif.
Solltest Du keinen Zugriff auf die Daten der Google Search Console haben, ist das auch kein Problem. Entscheide Dich für einen Tarif und informiere uns per E-Mail darüber. Wir tracken daraufhin einen Monat lang Deine Log-Daten auf die Gesamtsumme pro Tag und informieren Dich dann über den passenden Tarif.
Wie lange gelten die Einführungspreise?
Einmal abgeschlossene Einführungspreise sind zeitlich unbegrenzt und gelten daher über die gesamte Vertragsdauer.
Was passiert wenn ich die maximalen Requests pro Tag überschreite?
Das ist in jedem Fall kein Beinbruch.
Solltest Du allerdings über einen konstanten Zeitraum von 90 Tagen die durchschnittliche Höchstgrenze an Requests Deines gewählten Tarifs überschreiten, werden wir Dich darüber informieren und Deinen Tarif in Abstimmung mit Dir fair anpassen.
Was passiert nach meiner Bestellung?
Sobald Deine Bestellung bei uns eingegangen ist, werden wir für Dich Deine eigene Infrastruktur auf einem unserer Server einrichten.
Sobald dieser erste Schritt getan ist (dauert max. einen Werktag) werden wir Dich per E-Mail informieren. In unserer E-Mail werden wir Dir dann Deine Möglichkeiten aufzeigen, wie Du uns Deine Logfiles übermitteln kannst. Bitte entscheide Dich für eine Variante und gib uns so rasch wie möglich dazu Feedback.
Sobald wir alle nötigen Informationen haben, setzen wir Deinen Account vollständig auf (dieser Prozess ist nur einmalig nötig).
Fazit: Spätestens eine Woche nach Deiner Bestellung solltest Du bereits mit Deinen Logfile-Analysen starten können.
Sind die Analysen & Auswertung im Tool tagaktuell?
Ja, vom Vortag.
Die Logdaten werden immer auf Tagesbasis gezogen. In der Nacht ab ca. 00.00 Uhr werden die Logdaten vom Vortag gezogen, gespeichert und anschließend beginnt der crawlOPTIMIZER mit allen notwendigen Aggregationen, damit Dir in der Früh alle Analysen & Auswertungen fertig zur Verfügung stehen. So kannst du bis zu 60 Monate analysieren und auswerten.
Gibt es ein LIVE-Monitoring des Googlebots?
Nein, das haben wir nicht eingeplant.
Aufgrund der enormen Komplexität der fertigen Analysen und Auswertungen die etliche Stunden Server-Ressourcen in Kauf nehmen, ist ein LIVE-Monitoring leider nicht machbar. Dafür bekommst Du fixfertige Analysen & Auswertungen, die Dir Deinen Berufsalltag signifikant erleichtern.
Alle Analysen & Auswertungen sind daher vom Vortag und älter (bis zu 60 Monate).
ERSTMALIGES SETUP
Wie kann ich meine Logfiles an den crawlOPTIMIZER übermitteln?
Wir bieten Dir vier einfache Möglichkeiten an, uns Deine Logfiles automatisiert und dauerhaft zu übermitteln. Das Setup muss nur einmalig eingerichtet werden und ist in der Praxis nicht aufwändig.
1. (S)FTP-Download
Wir bekommen einen eigenen, sicheren Zugriff auf Deinen (S)FTP-Server (gerne auch via IP-Access abgesichert), wo Deine Logfiles täglich abgelegt werden. Wir downloaden die Logfiles täglich vollautomatisiert und selbsttätig.
2. SFTP-Upload
Wir stellen Dir einen eigenen SFTP-Server zur Verfügung. Du bekommt von uns alle Zugangsdaten & Zugriffsrecht. Und Du legst Deine Logfiles täglich, automatisiert auf unserem SFTP-Server ab.
3. CURL-Download
Wir bekommen via URL die Möglichkeit, Deine Logfiles täglich zu ziehen.
4. Täglich per E-Mail (für kleine bis mittlere Webseiten geeignet)
Du kannst uns Deine komprimierten Logfiles täglich per E-Mail übersenden. Hierfür bekommst Du von uns eine eigene E-Mail Adresse, an die Du Deine Logs sendest. Bitte beachte jedoch, dass jede E-Mail nicht größer als 10MB sein sollte. Du kannst uns aber natürlich mehrere E-Mails à 10MB pro Tag senden.
Solltest Du eine weitere hier nicht aufgelistete Variante mehr bevorzugen, lass es uns einfach wissen und wir richten alles nach Deinen Vorgaben ein.
Wie weiß ich, ob meine Logfiles geeignet sind?
Grundsätzlich können wir mit Logfiles von allen unterschiedlichen Servern (Apache, nginx, etc.) arbeiten, da wir alle Logfiles einmalig und individuell einrichten. Logfiles im JSON-Format können auch problemlos verarbeitet werden.
Du kannst uns aber trotzdem gerne per E-Mail einen Auszug Deiner Logfiles übersenden. Wir prüfen sie und geben Dir asap Feedback.
Muss die IT die Logfiles irgendwie aufbereiten bzw. vorfiltern?
Ja, bitte.
Da wir keine userbezogenen Daten erhalten und verarbeiten wollen, muss die IT folgende Vorfilterung der Logfiles durchführen:
Vorfilterung der Access-Logs nach dem Begriff „google“ innerhalb des „User Agents„. D.h. der Begriff „google“ muss innerhalb des User Agent-Strings vorkommen (egal in welcher Schreibweise. Positive Beispiele: Googlebot, google, Google, GOOGLE). Alle übrigen Logeinträge ohne „google“ wollen wir im Idealfall nicht bekommen und sollen daher nicht abgelegt / übermittelt werden.
Zwei Beispiele:
- Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
- Googlebot-Image/1.0
Sollten wider Erwarten versehentlich doch andere Logeinträge übermittelt worden sein, werden diese beim Import der Logfiles durch eine automatische Prüfung identifiziert und unwiderruflich gelöscht.
Wie ermittelt ihr den echten Googlebot?
Mittels Reverse-DNS wird jede uns noch nicht bekannte IP geprüft, ob sie auch tatsächlich von Google stammt.
Unsere Engine arbeitet selbstlernend und erweitert so automatisch die Anzahl der uns bekannten Google-IPs, um noch schneller ein Matching durchzuführen.
Crawlt ihr selbst auch meine Webseite?
Ja! Um den crawlOPTIMIZER allumfänglich nutzen zu können, ist ein Crawling Deiner Webseite(n) nötig. Das Crawling findet i.d.R. einmal pro Woche nachts statt und wird nach Deinen individuellen Vorgaben eingestellt.
Was crawlen wir?
Unser Crawler crawlt lediglich alle Einträge (URLs) aus Deinen XML-Sitemaps.
Folgende Crawling-Standardwerte sind in den Settings hinterlegt:
- Sitemap Import Weekday: Monday
- Sitemap Import Time: 01:00:00 Uhr (CET)
- Crawl Start Time: 02:00:00 Uhr (CET)
- Crawl End Time: 06:00:00 Uhr (CET)
- Crawl Rate: 5 URLs pro Sekunde
Diese Standardwerte können jederzeit durch den Kunden im Menüpunkt „Settings“ individuell angepasst werden.
Wenn kein Crawling der XML-Sitemap(s) gewünscht ist, muss die Crawl Rate in den „Settings“ auf den Wert „0“ gesetzt werden. Dies hätte dann zur Folge, dass kein Crawling durch den crawlOPTIMIZER stattfindet. Im Falle eines „Nicht-Crawlings“ der XML-Sitemaps kann die Auswertung „Do not waste your crawl budget (XML-Sitemap Check)“ im Dashboard nicht angezeigt werden, da die benötigten Crawling-Informationen fehlen.
Weitere Informationen:
- Die in den „Settings“ maximal einstellbare Crawl Rate ist mit 10 URLs pro Sekunde limitiert. Höhere Crawl Rates nur auf Anfrage.
- Der crawlOPTIMIZER User Agent ist wie folgt aufgebaut:
Mozilla/5.0 (compatible; crawlOPTIMIZER/0.0.1; +https://www.crawloptimizer.com)
Wie lautet euer User Agent?
Mozilla/5.0 (compatible; crawlOPTIMIZER/0.0.1; +https://www.crawloptimizer.com)
GOOGLE SEARCH CONSOLE
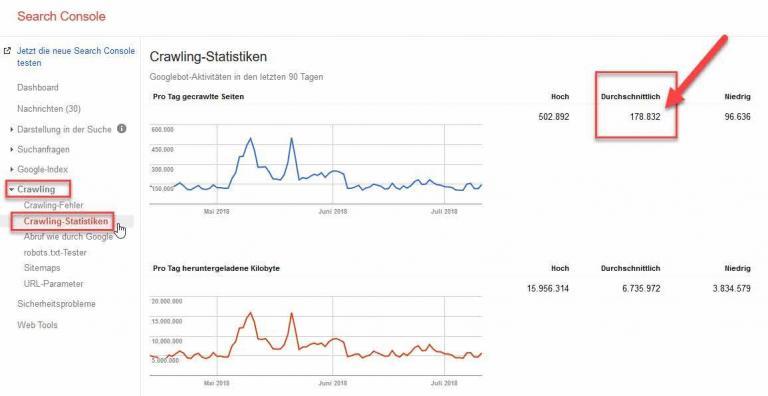
Wo finde ich in der Google Search Console die Anzahl der Googlebot-Zugriffe?
- Melde Dich in Deiner Google Search Console an
- Klicke auf „Crawling“
- Danach auch „Crawling-Statistiken“
- Dort findest Du die „Average Crawls“
Spezifikation für IT
Kontakt







